Data Modeling Patterns
Data Modelling Patterns from the MongoDB blog and that youtube video
NoSQL
Relational Data Model relies on normalization for some reason. Storing data in tables, and then having to do complex database level queries and joins in order to get the data in the format we need for the user-read is annoying when you’re database is super normalized. This is called impedance mismatch.
Common No-SQL Data Patterns:
- Embedded Pattern: Allows you to keep all information relevant to a specific data type within the same document.
- Aggregate Pattern: Used to store attributes of a larger embedded (or separate) collection within a document for quicker access and reads.
MongoDB Data Modelling Best Practices:
- Rule 1: Favor embedding unless there is a compelling reason not to.
- Rule 2: Needing to access an object on its own is a compelling reason not to embed it.
- Rule 3: Avoid joins and lookups if possible, but don’t be afraid if they can provide a better schema design.
- Rule 4: Arrays should not grow without bound. If there are more than a couple of hundred documents on the many side, don’t embed them; if there are more than a few thousand documents on the many side, don’t use an array of ObjectID references. High-cardinality arrays are a compelling reason not to embed.
- Rule 5: As always, with MongoDB, how you model your data depends entirely on your particular application’s data access patterns. You want to structure your data to match the ways that your application queries and updates it.
Relation Model
Normalization is the process of reducing/eliminating data redundancy.
The rule of thumb is:
DONT STORE REDUNDANT DATA. Your state is your source of truth, dont multiply it, you answer to one state, everything depends on it. The moment you have copies, things can go wrong.
The only time you denormalize data is when you want to optimize for performance. Think about it, before you do.
Academic Rules:
1NF
-> Don’t have duplicate rows. Add a primary key gang. Don’t nest tables.
Every row must have a unique primary key.
There can be no nested tables.
2NF
-> If a column depends on part of the primary key, then move it and that part of the key to a seperate table.
Non PK columns must be dependant / related to the entire primary key, not just a part of it.
(primary key = combination of columns to create unique identifier here, not just the normal “id”, here first_name and last_name combined become the PK)

3NF
-> Two random columns in a table cannot depend on one or the other. Relations are always based on the PK for a table, not any other columns.
All columns that are not the PK must only be dependant on the PK, nothing else.
BCNF
-> Dont let the PK be dependant on a non-PK in the table. Don’t know how to simplify this, its a for a very weird edge case only anyway.
A column thats part of primary key may not be dependant on any columns that are not part of the primary key.
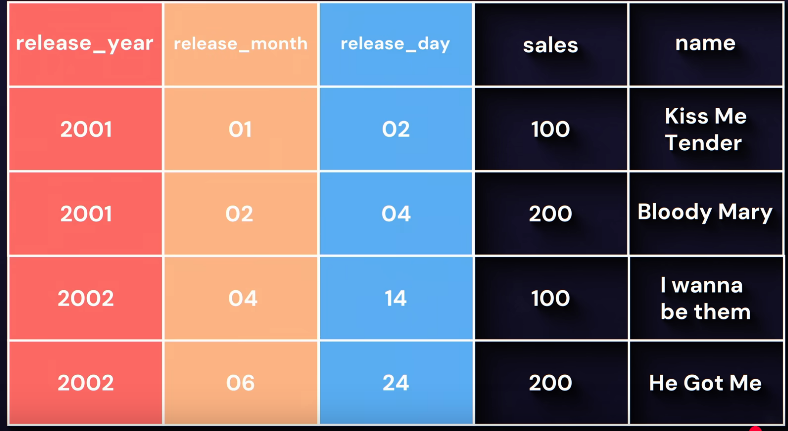
In this example, they used release year + sales as primary key, but they also had a release date (dd-mm-yyyy) column, which they later normalized into this:
Indexes
Inverted indexes are just like lookup tables (hash-maps?) of things we want to find quickly, and where they are located.
"brown" → [doc #5, doc #420, doc #69420...]
"fox" → [doc #5, doc #99, doc #420...]Not sure if these are the same as actual indexes though, have to look into that.